Qualities of a Smooth Queueing System
This morning, Eleni and I were reflecting on how our queueing system has evolved at OfficeLuv over the past year.
We now process thousands of jobs per second across hundreds of job types. Our queue reliability and performance allow us to keep our fast customer and admin response times while increasing scale and keeping our development costs and headcount down. Here’s everything we’ve configured or built into our queues that allow them to grow into the backbone of our architecture while, most importantly, not keeping us up at night.
Prioritization
Have a clear hierarchy of queues that allows you to prioritize jobs based on class/type/whatever. Often a queueing system will allow prioritization of jobs only, while maintaining a single queue. I think this is suboptimal, because you may want to apply optimization of a prioritization on a higher level than the job type. Separate queues allows for this.
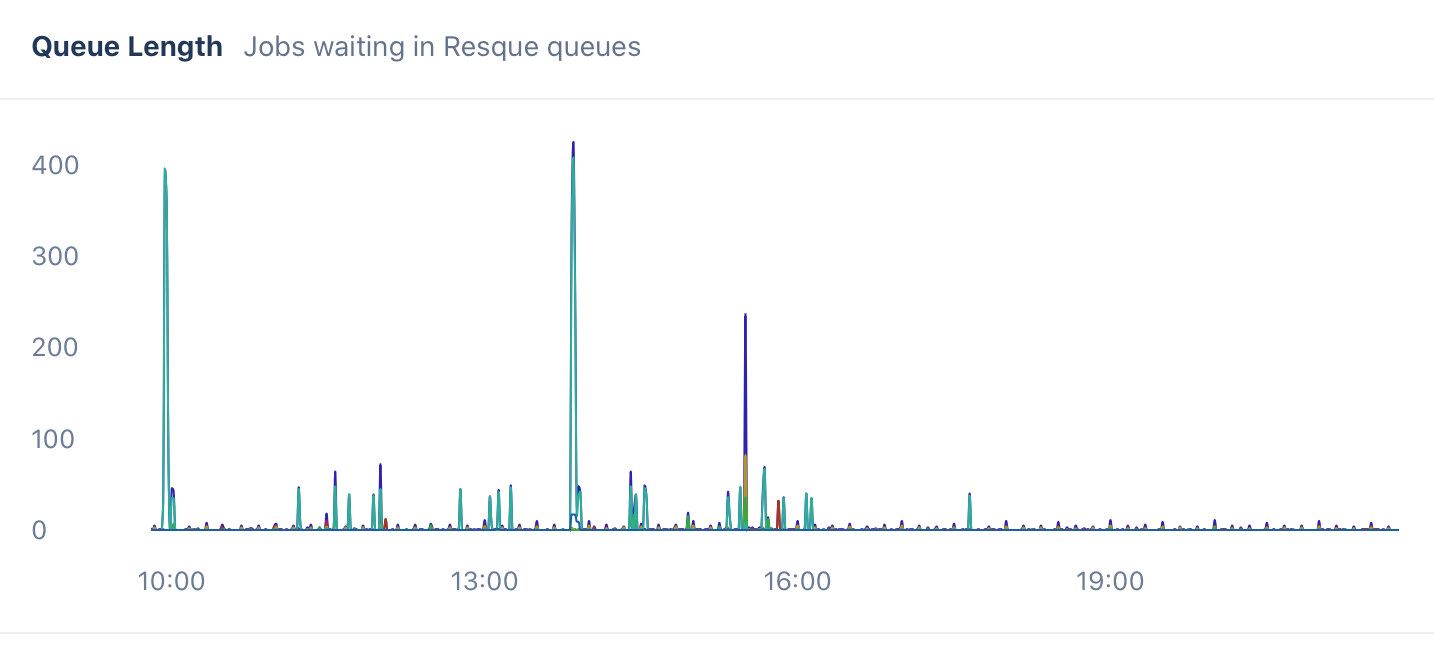
Plan for expansion of your queue hierarchy because you don’t know all the queues you’ll need down the road. For us, using Resque’s alphabetical prioritization scheme, this meant naming our queues with options to expand into subqueues between them. Our queue evolution has been:
- high, low, slow
- critical, high, low, slow
- critical, high, low, mailers, slow
- critical, high, low, mailers, slow, trailing
- critical, high, low, mailers, slow, trailing, unhurried
- critical, essential, high, low, mailers, slow, trailing, unhurried
Exception Handling
Whitelist exceptions to discard or retry instead of taking a blacklisting approach. Many queue systems will make it equally easy to take a whielisting or a blacklisting approach to the problem of retrying or discarding exceptions. You should definitely take a whitelisting approach, to remove any unexpected retries or discards. For example, you probably want to retry any jobs that are calling external APIs and receive a server error. Or you will probably want to discard jobs that deal with notifying users of a record that has been destroyed since the job was originally enqueued.
Retry jobs with jitter. When retrying a job, always add a variable delay (jitter) in between attempts. This eliminates a whole class of problems introduced by jobs of the same type or concern hitting a service in concert. Even if you don’t think this will be an issue internally, your external services will perform better if you treat them better.
Configure a dedicated failure queue for each queue. This allows your team or your queueing system to handle these failures (after retry and discard logic has been applied) separately. This is important once you have thousands of jobs flowing through your queues, as failures of different priority will necessitate different attention. If you’re operating at a lower rate, you can maintain a single failure queue until the volume necessitates it, as we did.
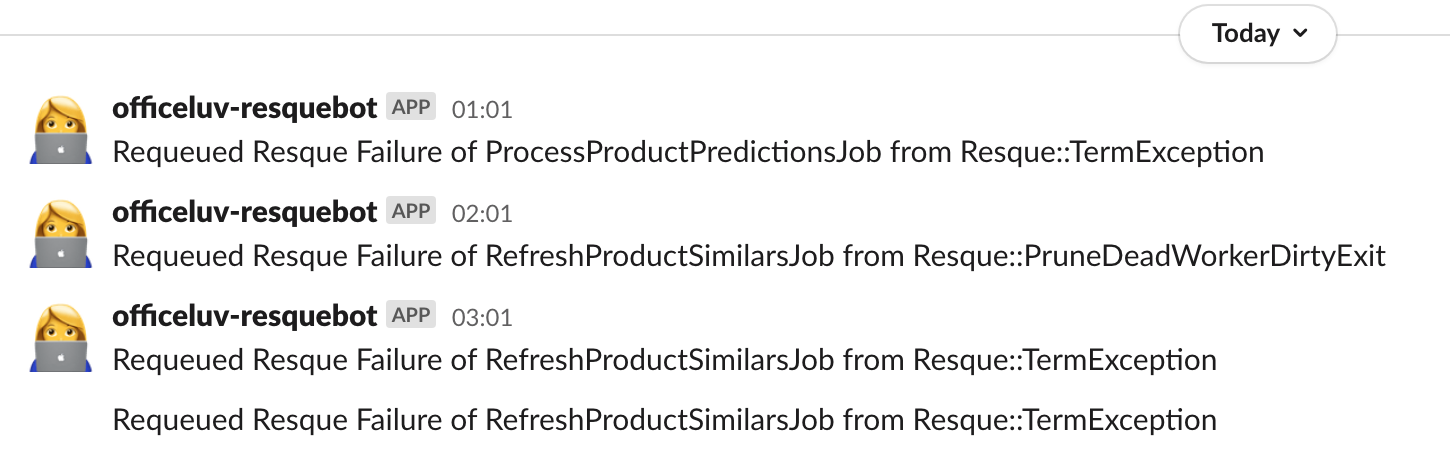
Have a system for requeueing out of the failure queues. This has been our most recent addition to the queueing system, but has eliminated a whole class of developer concerns. Essentially, we have retry logic that applies before a job is placed onto a failure queue. From a failure queue, we have separate workers that process those failures and attempt to handle them according to a secondary retry logic that applies only to specific low-level failures or repeated exceptions.
Introspection
Provide queue introspection by an external system or the queue itself. Queue observability is as important as any other system observability, and we have used it constantly. Whether it’s an external system or probes running through the queue itself (our approach) that reports on the queue depth, rate, etc., you should have a constant report of the queues’ health.
Have a notification system for failures and queue velocity changes so that you can understand the queues’ behavior. This was one of the first aspects that we built into our own queues so that we could manually handle failures. That’s fine to start, and will annoy you enough to build the requeueing logic. We have not yet built notifications for changes queue velocity, but we have recently seen some behaviors that could be better expected if we had such a notification.
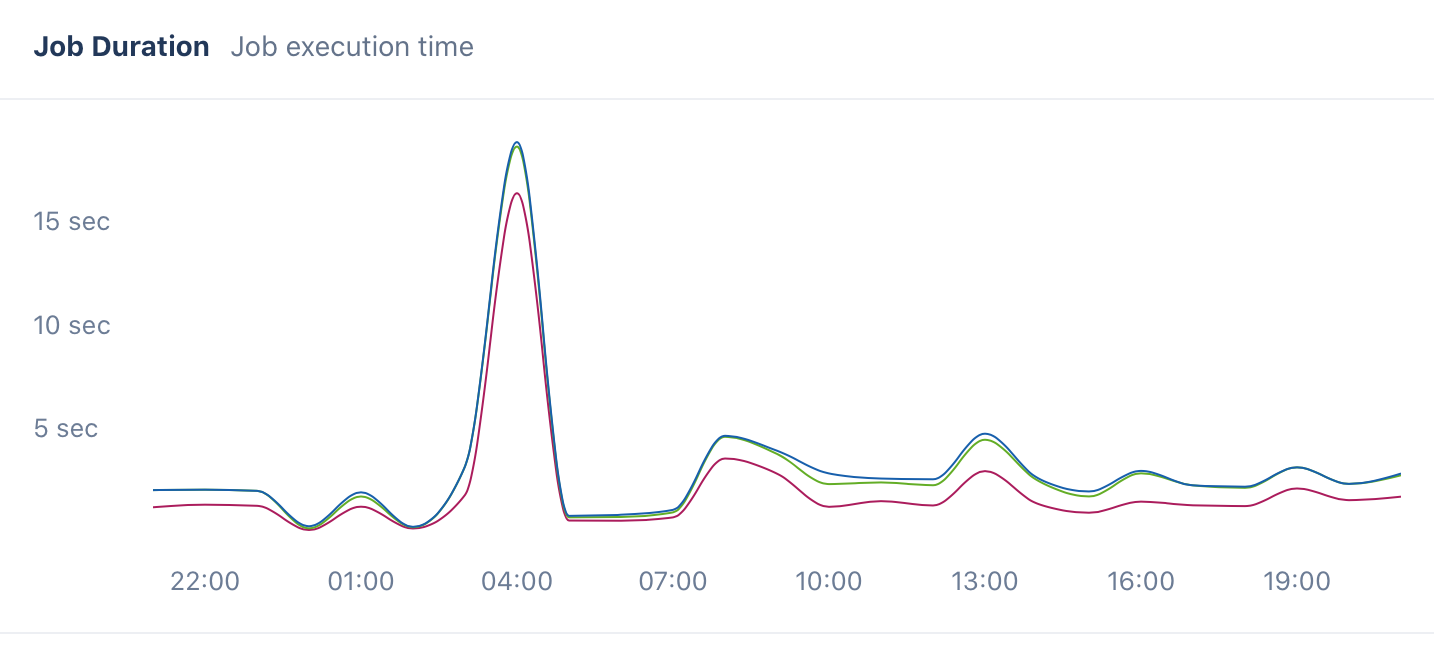
Have a method of estimating queue lead time. This becomes important if you want to have accurate and effective scaling algorithms. We take the approach of recording execution time for a sample of jobs of each type in our queue. Then, as our queue introspection probes report on the queue depth, workers, and more, they also report on the estimated execution time for each job currently in the queues. This allows our scaling algorithms to take not only queue depth but also queue lead time into account when scaling. This had been a convenient, though probably not required aspect of our scaling logic. We’ve used Appsignal to estimate durations pretty effectively, but any APM system should do.
Scaling
Scale queue workers based on the introspection described above. Maintaining a constant worker pool will be wasteful, so having a system of rules (simply a step function at first) to scale workers up or down based on queue depth saves you a ton of money in aggregate. A simple step function can evolve into a context-based algorithm, but scaling is a necessity. We’ve easily shaved off hundreds of dollars from our monthly bills by tweaking our queue scaling algorithms.
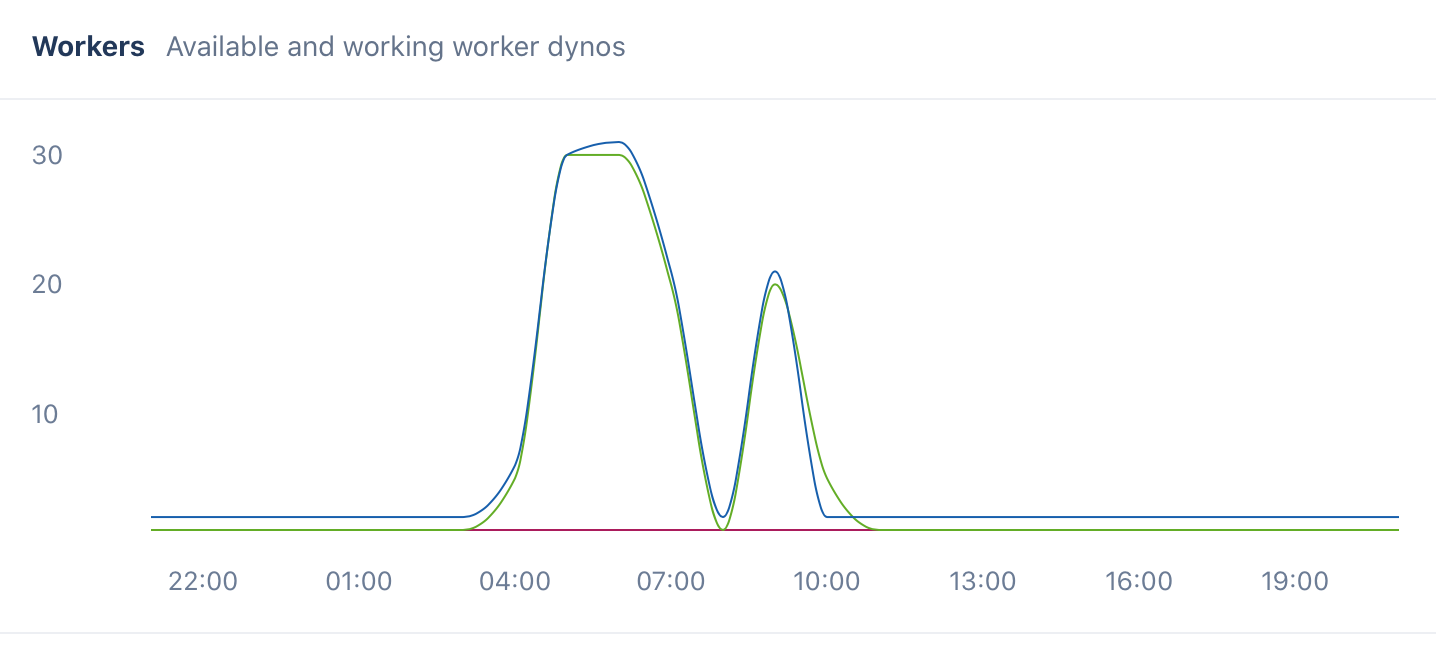
Scale at an interval that maps to your throughput change rate. Your scaling assessment and its effect must be commensurate with the acceleration or deceleration of your queue depth. So, if your queue depth changes during the day, but generally increases over the course of an hour, you should be introspecting your queues at a reasonable fraction of that rate. If your queue depth changes drastically minute to minute, you need to be introspecting once a second and you need to have your scaling commands take effect within a few seconds. If your scaling effects take longer than it takes for your queue to grow or shrink, your commands are out of date and will have unintended effects.
Though there are many queueing SAAS products out there, I’ve never seen one that provides all of this for you in one package. Luckily, any of these can be built by your own team. You won’t need all of these aspects when spinning up your application’s queueing infrastructure, but you will need them as you offload more work to the queue.